
DrissionPage的使用与说明
DrissionPage 特点
- 功能整合:它既能控制浏览器,也能收发数据包,还能将两者结合在一起。
- 兼顾效率与便捷:兼顾浏览器自动化的便利性和
requests的高效率。 - 不依赖 WebDriver:无需使用
webdriver,简化操作。 - 无需下载驱动:不依赖于不同浏览器版本的驱动程序。
- 运行速度更快:相较于传统方法,性能更优秀。
- 跨 iframe 查找元素:可以跨 iframe 查找元素,无需切换上下文。
- 多标签页操作:可同时操作多个标签页,无需切换。
- 数据包监听:内置方便的数据包监听功能。
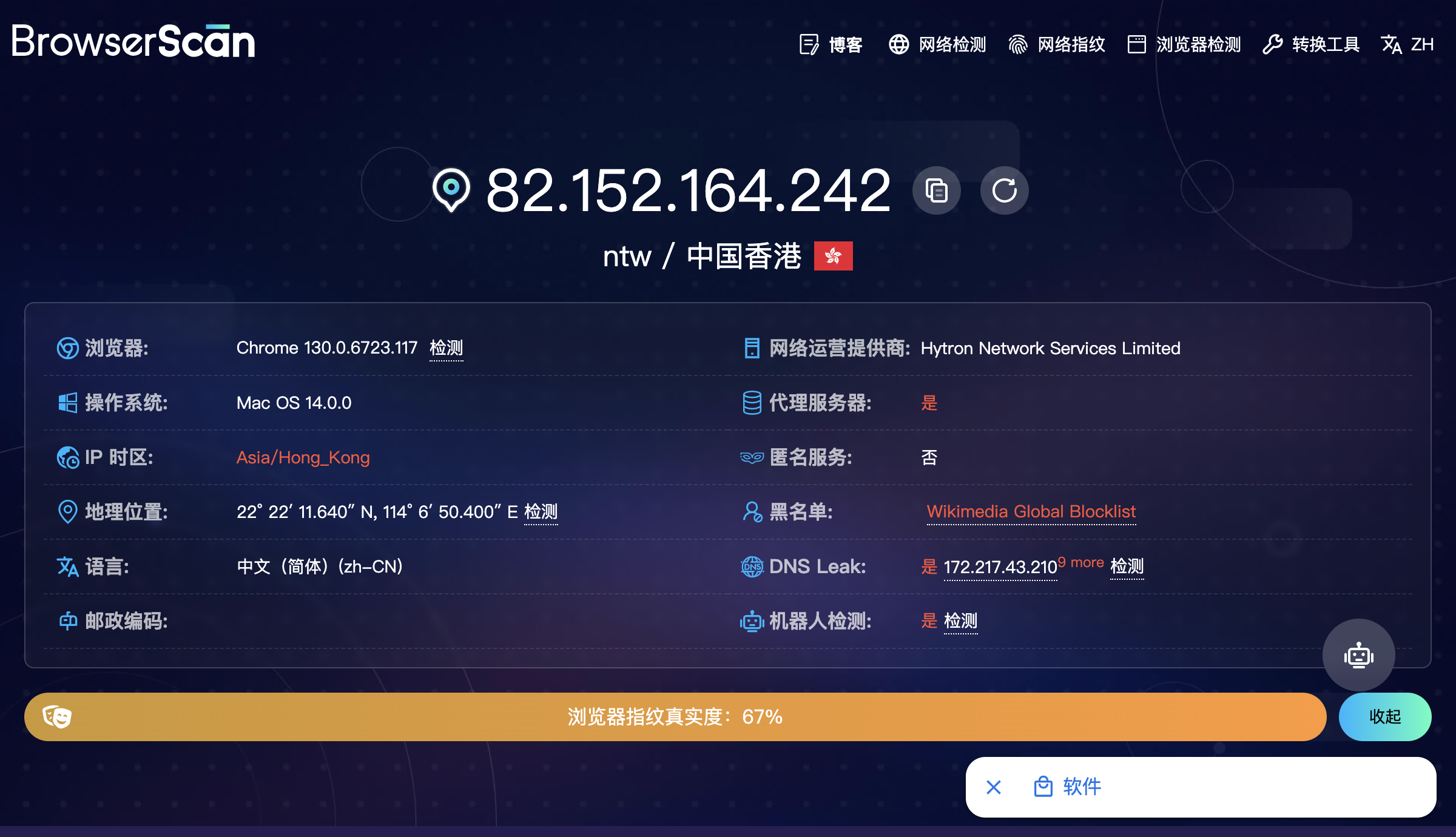
指纹特征对比
使用selenium控制浏览器

使用DrissionPage控制浏览器
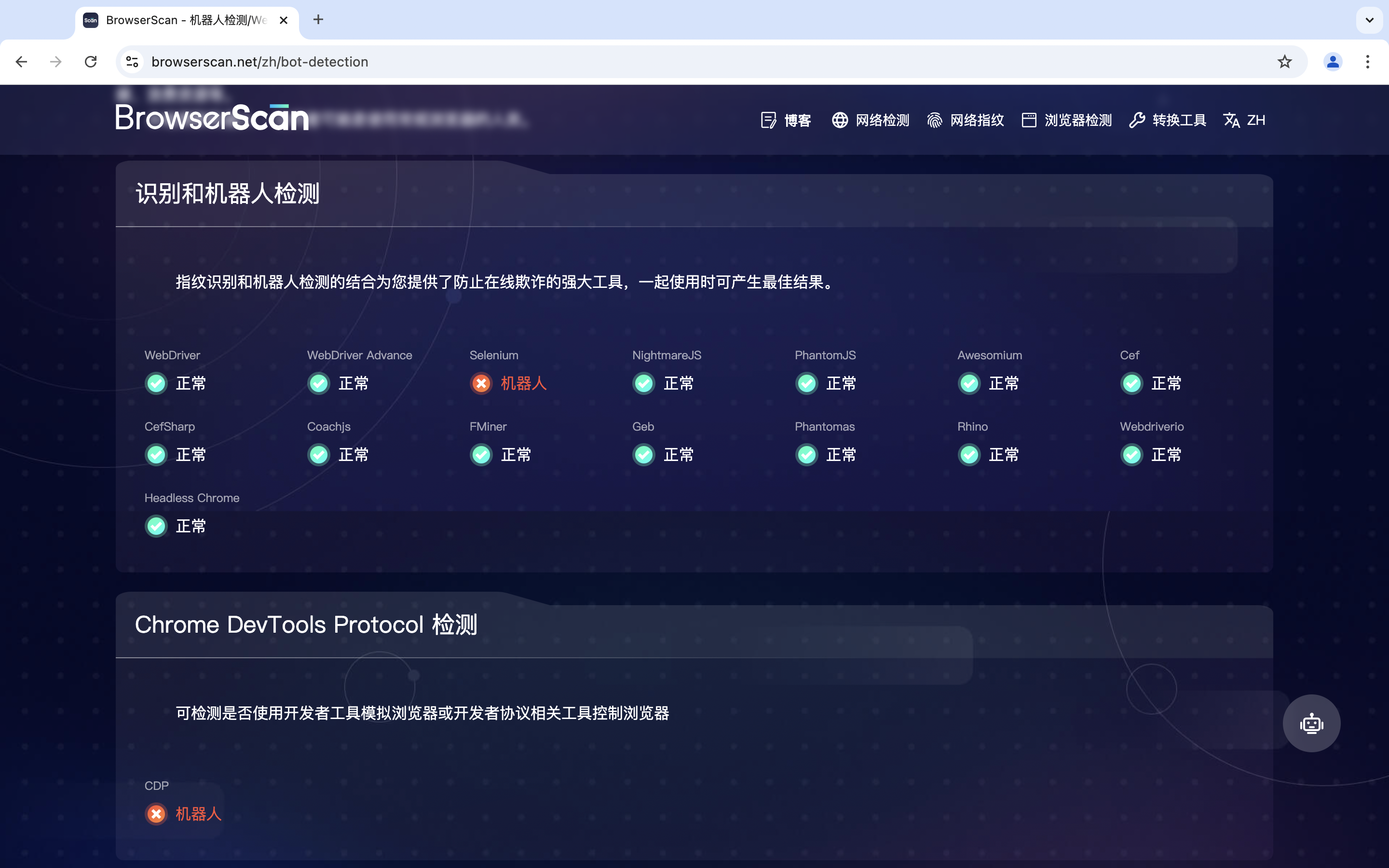
极简定位语法
使用 Selenium 查找元素:
1
element = WebDriverWait(driver, 10).until(ec.presence_of_element_located((By.XPATH, '//*[contains(text(), "some text")]')))
使用 DrissionPage 查找元素:
1
element = tab('some text', timeout=10)
同时操作多个标签页
1 | tab1 = browser.get_tab(1) |
安装 DrissionPage
1 | pip install DrissionPage |
DrissionPage 提供的功能模块
浏览器类、配置类、页面类:
1
from DrissionPage import ****
异常处理:
1
from DrissionPage.errors import ****
辅助工具:
1
from DrissionPage.common import ****
衍生对象(用于类型判断):
1
from DrissionPage.items import ****
启动浏览器的方式
自动获取 Chrome 路径:
1
2
3from DrissionPage import Chromium
tab = Chromium().latest_tab
tab.get('https://DrissionPage.cn')设置自定义 Chrome 路径:
1
2
3
4
5from DrissionPage import Chromium, ChromiumOptions
path = r'D:\Chrome\Chrome.exe' # 请改为你电脑内Chrome可执行文件路径
co = ChromiumOptions().set_browser_path(path)
tab = Chromium(co).latest_tab
tab.get('https://DrissionPage.cn')指定端口或地址:
1
2browser = Chromium(9333)
browser = Chromium('127.0.0.1:9333')
查找元素的写法
根据 ID 查找元素:
1
div1 = tab.ele('#one') # 获取 id 为 one 的元素
根据 name 属性查找元素:
1
p1 = tab.ele('@name=row1') # 获取 name 属性为 row1 的元素
查找所有 div 元素:
1
div_list = tab.eles('tag:div') # 获取所有div元素
根据文本查找元素:
1
t1 = tab.ele('@text()=第一行') # 获取第一个文本为“第一行”的元素
查找元素的匹配符与模式
**单属性匹配符
@**:1
tab.ele('@id=one') # 匹配 id 为 "one" 的元素
**多属性与匹配符
@@**:1
ele = tab.ele('@@class=p_cls@@text()=第三行') # 查找 class 为 p_cls 且文本为 "第三行" 的元素
**多属性或匹配符
@|**:1
eles = tab.eles('@|id=row1@|id=row2') # 查找所有 id 为 row1 或 row2 的元素
**否定匹配符
@!**:1
2ele = tab.ele('@!id=one') # 获取第一个 id 不等于 "one" 的元素
ele = tab.ele('@!class') # 匹配没有 class 属性的元素
匹配模式
**精确匹配
=**:1
ele = tab.ele('@id=row1') # 获取 id 属性为 'row1' 的元素
**模糊匹配
:**:1
ele = tab.ele('@id:ow') # 获取 id 属性包含 'ow' 的元素
**匹配结尾
$**:1
ele = tab.ele('@id$w1') # 获取 id 属性以 'w1' 结尾的元素
定位语法
基本用法
| 写法 | 精确匹配 | 模糊匹配 | 匹配开头 | 匹配结尾 | 说明 |
|---|---|---|---|---|---|
@属性名 |
@属性名= |
@属性名: |
@属性名^ |
@属性名$ |
按某个属性查找 |
@!属性名 |
@!属性名= |
@!属性名: |
@!属性名^ |
@!属性名$ |
查找属性不符合指定条件的元素 |
text |
text= |
text:或不写 |
text^ |
text$ |
按某个文本查找 |
@text() |
@text()= |
@text(): |
text()^ |
text()$ |
text与@或@@配合使用时改为text(),常用于多条件匹配 |
tag |
tag=或tag: |
无 | 无 | 无 | 查找某个类型的元素 |
@tag() |
@tag()=或@tag(): |
无 | 无 | 无 | 组合使用时查找某个类型的元素 |
xpath |
xpath=或xpath: |
无 | 无 | 无 | 用 xpath 方式查找元素 |
css |
css=或css: |
无 | 无 | 无 | 用 css selector 方式查找元素 |
简写用法
| 原写法 | 简化写法 | 说明 |
|---|---|---|
@id |
# |
表示 id 属性 |
@class |
. |
表示 class 属性 |
text |
tx |
按文本匹配 |
@text() |
@tx() |
按文本查找 |
tag |
t |
按标签类型匹配 |
@tag() |
@t() |
按元素名查找 |
xpath |
x |
用 xpath 方式查找元素 |
css |
c |
用 css selector 方式查找元素 |
模式切换
这样可以实现先通过控制浏览器登陆后再收发数据包的形式访问网页。
1 | from DrissionPage import Chromium |
收发数据包是封装了requests和lxml,简化了代码。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 昕云!